Sample Merge
In order to further conduct larger-scale SV research, SDFA has developed a cohort-wide merging algorithm for SV sample merging at the population scale level. This algorithm is based on the SDF file and performs k-way merging on the basis of considering all SV data in an orderly manner:
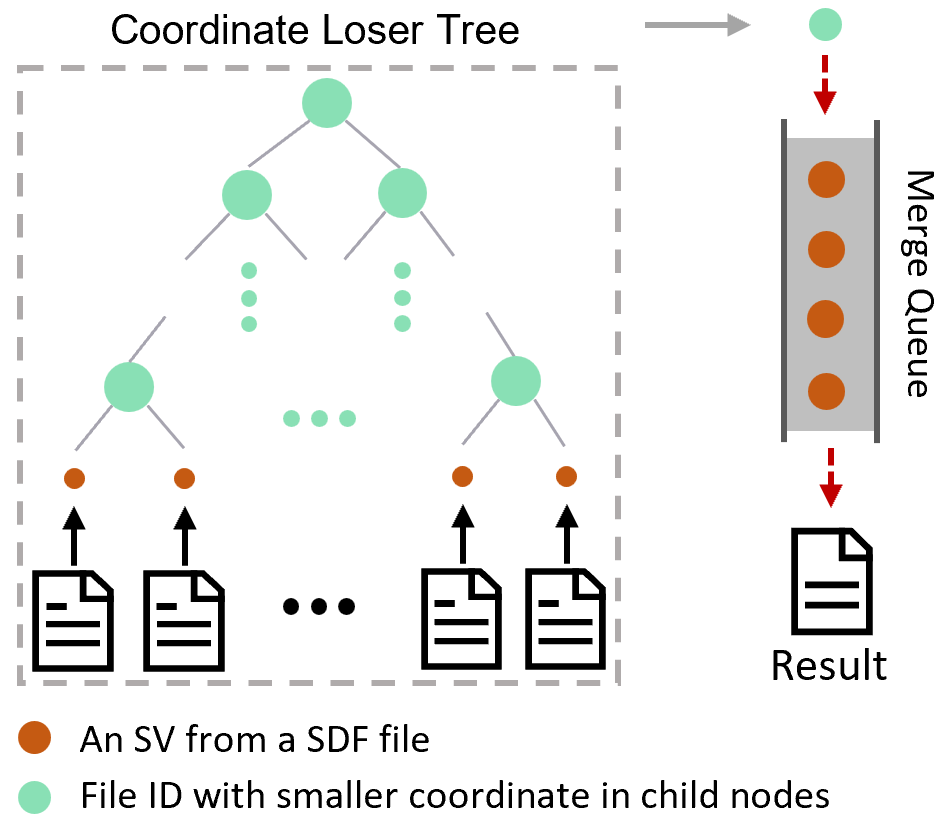
Currently, SDFA uses position to perform SV merging among samples, as follows:
SDFA maintains an ordered list of SVs of the same type and location, and adds SVs of the same type in ascending order of the minimum position. When a newly added SV (marked as $SV_{new}$) does not meet the merging conditions, all SVs in the current list will be popped and merged into one SV. The default merging conditions are as follows:
[!NOTE|label:Example 1]
SDFA merges the VCF files (including compressed files and SDF files) in the specified folder and outputs the merged results to the specified folder. The command line is as follows:
java -jar sdfa.jar -d ./data -o ./